数据拆分
前提
现在已经使用了 label-studio 工具直接生成了 yolo 格式的文件。需要对该数据做训练集、测试集、验证集的数据拆分。
由 chatGPT 生成的代码
python
# chatgpt 生成的代码 Splitting.py
import os
import argparse
import shutil
import random
def split_dataset(input_dir, output_dir):
# 创建输出目录
os.makedirs(output_dir, exist_ok=True)
os.makedirs(os.path.join(output_dir, 'images', 'train'), exist_ok=True)
os.makedirs(os.path.join(output_dir, 'images', 'val'), exist_ok=True)
os.makedirs(os.path.join(output_dir, 'images', 'test'), exist_ok=True)
os.makedirs(os.path.join(output_dir, 'labels', 'train'), exist_ok=True)
os.makedirs(os.path.join(output_dir, 'labels', 'val'), exist_ok=True)
os.makedirs(os.path.join(output_dir, 'labels', 'test'), exist_ok=True)
# 获取标签和图像文件列表
labels_dir = os.path.join(input_dir, 'labels')
images_dir = os.path.join(input_dir, 'images')
label_files = os.listdir(labels_dir)
image_files = os.listdir(images_dir)
# 随机打乱数据
random.shuffle(label_files)
# 计算数据集拆分的边界索引
num_samples = len(label_files)
train_size = int(0.8 * num_samples)
val_size = int(0.1 * num_samples)
# 拆分数据集并复制文件
train_labels = label_files[:train_size]
val_labels = label_files[train_size:train_size + val_size]
test_labels = label_files[train_size + val_size:]
for label_file in train_labels:
shutil.copy(os.path.join(labels_dir, label_file), os.path.join(output_dir, 'labels', 'train'))
shutil.copy(os.path.join(images_dir, label_file[:-4] + '.jpg'), os.path.join(output_dir, 'images', 'train'))
for label_file in val_labels:
shutil.copy(os.path.join(labels_dir, label_file), os.path.join(output_dir, 'labels', 'val'))
shutil.copy(os.path.join(images_dir, label_file[:-4] + '.jpg'), os.path.join(output_dir, 'images', 'val'))
for label_file in test_labels:
shutil.copy(os.path.join(labels_dir, label_file), os.path.join(output_dir, 'labels', 'test'))
shutil.copy(os.path.join(images_dir, label_file[:-4] + '.jpg'), os.path.join(output_dir, 'images', 'test'))
if __name__ == '__main__':
# 命令行参数解析
parser = argparse.ArgumentParser()
# chatgpt origin
# parser.add_argument('--input-dir', type=str, default="", help='输入目录')
# parser.add_argument('--output-dir', type=str, default="", help='输出目录')
parser.add_argument('--input-dir', type=str,
default="D:/code/python-workspace/yolo/yolov5-server-env-like/images/temp-air-inflation/t1/origin",
help='输入目录')
parser.add_argument('--output-dir', type=str,
default="D:/code/python-workspace/yolo/yolov5-server-env-like/images/temp-air-inflation/t1/res",
help='输出目录')
args = parser.parse_args()
# 调用函数拆分数据集
split_dataset(args.input_dir, args.output_dir)运行脚本
bash
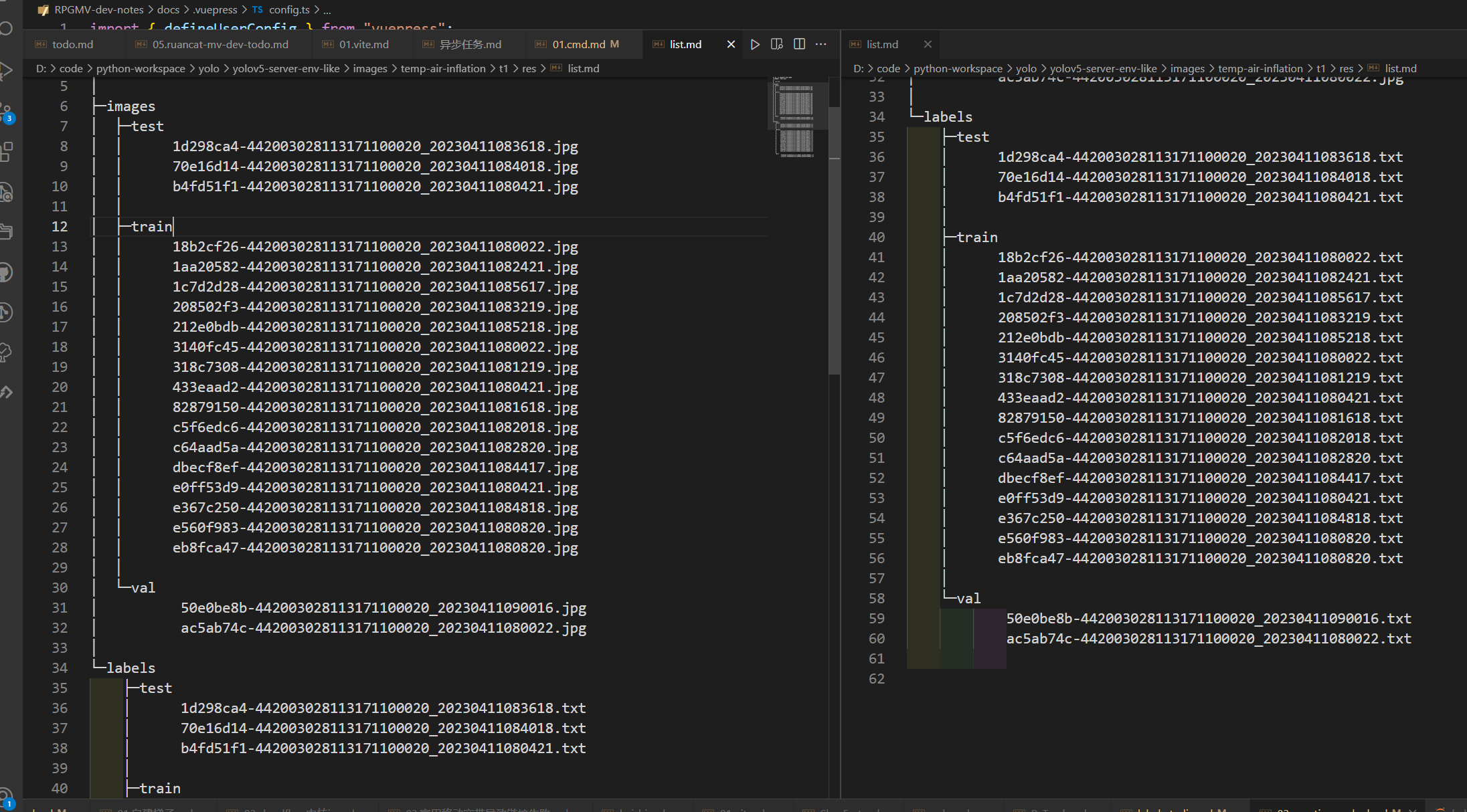
py Splitting.py数据拆分效果如下
贡献者
 ruan-cat
ruan-cat